OpenCV如何扫描图像、利用查找表和计时¶
测试用例¶
这里我们测试的,是一种简单的颜色缩减方法。如果矩阵元素存储的是单通道像素,使用C或C++的无符号字符类型,那么像素可有256个不同值。但若是三通道图像,这种存储格式的颜色数就太多了(确切地说,有一千六百多万种)。用如此之多的颜色可能会对我们的算法性能造成严重影响。其实有时候,仅用这些颜色的一小部分,就足以达到同样效果。
这种情况下,常用的一种方法是 颜色空间缩减 。其做法是:将现有颜色空间值除以某个输入值,以获得较少的颜色数。例如,颜色值0到9可取为新值0,10到19可取为10,以此类推。
uchar (无符号字符,即0到255之间取值的数)类型的值除以 int 值,结果仍是 char 。因为结果是char类型的,所以求出来小数也要向下取整。利用这一点,刚才提到在 uchar 定义域中进行的颜色缩减运算就可以表达为下列形式:
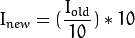
这样的话,简单的颜色空间缩减算法就可由下面两步组成:一、遍历图像矩阵的每一个像素;二、对像素应用上述公式。值得注意的是,我们这里用到了除法和乘法运算,而这两种运算又特别费时,所以,我们应尽可能用代价较低的加、减、赋值等运算替换它们。此外,还应注意到,上述运算的输入仅能在某个有限范围内取值,如 uchar 类型可取256个值。
由此可知,对于较大的图像,有效的方法是预先计算所有可能的值,然后需要这些值的时候,利用查找表直接赋值即可。查找表是一维或多维数组,存储了不同输入值所对应的输出值,其优势在于只需读取、无需计算。
我们的测试用例程序(以及这里给出的示例代码)做了以下几件事:以命令行参数形式读入图像(可以是彩色图像,也可以是灰度图像,由命令行参数决定),然后用命令行参数给出的整数进行颜色缩减。目前,OpenCV主要有三种逐像素遍历图像的方法。我们将分别用这三种方法扫描图像,并将它们所用时间输出到屏幕上。我想这样的对比应该很有意思。
你可以从 这里 下载源代码,也可以找到OpenCV的samples目录,进入cpp的tutorial_code的core目录,查阅该程序的代码。程序的基本用法是:
how_to_scan_images imageName.jpg intValueToReduce [G]
最后那个参数是可选的。如果提供该参数,则图像以灰度格式载入,否则使用彩色格式。在该程序中,我们首先要计算查找表。
int divideWith; // convert our input string to number - C++ style
stringstream s;
s << argv[2];
s >> divideWith;
if (!s)
{
cout << "Invalid number entered for dividing. " << endl;
return -1;
}
uchar table[256];
for (int i = 0; i < 256; ++i)
table[i] = divideWith* (i/divideWith);
这里我们先使用C++的 stringstream 类,把第三个命令行参数由字符串转换为整数。然后,我们用数组和前面给出的公式计算查找表。这里并未涉及有关OpenCV的内容。
另外有个问题是如何计时。没错,OpenCV提供了两个简便的可用于计时的函数 getTickCount() 和 getTickFrequency() 。第一个函数返回你的CPU自某个事件(如启动电脑)以来走过的时钟周期数,第二个函数返回你的CPU一秒钟所走的时钟周期数。这样,我们就能轻松地以秒为单位对某运算计时:
double t = (double)getTickCount();
// 做点什么 ...
t = ((double)getTickCount() - t)/getTickFrequency();
cout << "Times passed in seconds: " << t << endl;
图像矩阵是如何存储在内存之中的?¶
在我的教程 Mat - 基本图像容器 中,你或许已了解到,图像矩阵的大小取决于我们所用的颜色模型,确切地说,取决于所用通道数。如果是灰度图像,矩阵就会像这样:
![\newcommand{\tabItG}[1] { \textcolor{black}{#1} \cellcolor[gray]{0.8}}
\begin{tabular} {ccccc}
~ & \multicolumn{1}{c}{Column 0} & \multicolumn{1}{c}{Column 1} & \multicolumn{1}{c}{Column ...} & \multicolumn{1}{c}{Column m}\\
Row 0 & \tabItG{0,0} & \tabItG{0,1} & \tabItG{...} & \tabItG{0, m} \\
Row 1 & \tabItG{1,0} & \tabItG{1,1} & \tabItG{...} & \tabItG{1, m} \\
Row ... & \tabItG{...,0} & \tabItG{...,1} & \tabItG{...} & \tabItG{..., m} \\
Row n & \tabItG{n,0} & \tabItG{n,1} & \tabItG{n,...} & \tabItG{n, m} \\
\end{tabular}](../../../../_images/math/d741bf066ad4641450e60523988450519478814d.png)
而对多通道图像来说,矩阵中的列会包含多个子列,其子列个数与通道数相等。例如,RGB颜色模型的矩阵:
![\newcommand{\tabIt}[1] { \textcolor{yellow}{#1} \cellcolor{blue} & \textcolor{black}{#1} \cellcolor{green} & \textcolor{black}{#1} \cellcolor{red}}
\begin{tabular} {ccccccccccccc}
~ & \multicolumn{3}{c}{Column 0} & \multicolumn{3}{c}{Column 1} & \multicolumn{3}{c}{Column ...} & \multicolumn{3}{c}{Column m}\\
Row 0 & \tabIt{0,0} & \tabIt{0,1} & \tabIt{...} & \tabIt{0, m} \\
Row 1 & \tabIt{1,0} & \tabIt{1,1} & \tabIt{...} & \tabIt{1, m} \\
Row ... & \tabIt{...,0} & \tabIt{...,1} & \tabIt{...} & \tabIt{..., m} \\
Row n & \tabIt{n,0} & \tabIt{n,1} & \tabIt{n,...} & \tabIt{n, m} \\
\end{tabular}](../../../../_images/math/154cd030d6aa7d29c35852ac468a3e3e14b882bf.png)
注意到,子列的通道顺序是反过来的:BGR而不是RGB。很多情况下,因为内存足够大,可实现连续存储,因此,图像中的各行就能一行一行地连接起来,形成一个长行。连续存储有助于提升图像扫描速度,我们可以使用 isContinuous() 来去判断矩阵是否是连续存储的. 相关示例会在接下来的内容中提供。
1.高效的方法 Efficient Way¶
说到性能,经典的C风格运算符[](指针)访问要更胜一筹. 因此,我们推荐的效率最高的查找表赋值方法,还是下面的这种:
Mat& ScanImageAndReduceC(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() != sizeof(uchar));
int channels = I.channels();
int nRows = I.rows * channels;
int nCols = I.cols;
if (I.isContinuous())
{
nCols *= nRows;
nRows = 1;
}
int i,j;
uchar* p;
for( i = 0; i < nRows; ++i)
{
p = I.ptr<uchar>(i);
for ( j = 0; j < nCols; ++j)
{
p[j] = table[p[j]];
}
}
return I;
}
这里,我们获取了每一行开始处的指针,然后遍历至该行末尾。如果矩阵是以连续方式存储的,我们只需请求一次指针、然后一路遍历下去就行。彩色图像的情况有必要加以注意:因为三个通道的原因,我们需要遍历的元素数目也是3倍。
这里有另外一种方法来实现遍历功能,就是使用 data , data会从 Mat 中返回指向矩阵第一行第一列的指针。注意如果该指针为NULL则表明对象里面无输入,所以这是一种简单的检查图像是否被成功读入的方法。当矩阵是连续存储时,我们就可以通过遍历 data 来扫描整个图像。例如,一个灰度图像,其操作如下:
uchar* p = I.data;
for( unsigned int i =0; i < ncol*nrows; ++i)
*p++ = table[*p];
这回得出和前面相同的结果。但是这种方法编写的代码可读性方面差,并且进一步操作困难。同时,我发现在实际应用中,该方法的性能表现上并不明显优于前一种(因为现在大多数编译器都会对这类操作做出优化)。
2.迭代法 The iterator (safe) method¶
在高性能法(the efficient way)中,我们可以通过遍历正确的 uchar 域并跳过行与行之间可能的空缺-你必须自己来确认是否有空缺,来实现图像扫描,迭代法则被认为是一种以更安全的方式来实现这一功能。在迭代法中,你所需要做的仅仅是获得图像矩阵的begin和end,然后增加迭代直至从begin到end。将*操作符添加在迭代指针前,即可访问当前指向的内容。
Mat& ScanImageAndReduceIterator(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() != sizeof(uchar));
const int channels = I.channels();
switch(channels)
{
case 1:
{
MatIterator_<uchar> it, end;
for( it = I.begin<uchar>(), end = I.end<uchar>(); it != end; ++it)
*it = table[*it];
break;
}
case 3:
{
MatIterator_<Vec3b> it, end;
for( it = I.begin<Vec3b>(), end = I.end<Vec3b>(); it != end; ++it)
{
(*it)[0] = table[(*it)[0]];
(*it)[1] = table[(*it)[1]];
(*it)[2] = table[(*it)[2]];
}
}
}
return I;
}
对于彩色图像中的一行,每列中有3个uchar元素,这可以被认为是一个小的包含uchar元素的vector,在OpenCV中用 Vec3b 来命名。如果要访问第n个子列,我们只需要简单的利用[]来操作就可以。需要指出的是,OpenCV的迭代在扫描过一行中所有列后会自动跳至下一行,所以说如果在彩色图像中如果只使用一个简单的 uchar 而不是 Vec3b 迭代的话就只能获得蓝色通道(B)里的值。
3. 通过相关返回值的On-the-fly地址计算¶
事实上这个方法并不推荐被用来进行图像扫描,它本来是被用于获取或更改图像中的随机元素。它的基本用途是要确定你试图访问的元素的所在行数与列数。在前面的扫描方法中,我们观察到知道所查询的图像数据类型是很重要的。这里同样的你得手动指定好你要查找的数据类型。下面的代码中是一个关于灰度图像的示例(运用 + at() 函数):
Mat& ScanImageAndReduceRandomAccess(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() != sizeof(uchar));
const int channels = I.channels();
switch(channels)
{
case 1:
{
for( int i = 0; i < I.rows; ++i)
for( int j = 0; j < I.cols; ++j )
I.at<uchar>(i,j) = table[I.at<uchar>(i,j)];
break;
}
case 3:
{
Mat_<Vec3b> _I = I;
for( int i = 0; i < I.rows; ++i)
for( int j = 0; j < I.cols; ++j )
{
_I(i,j)[0] = table[_I(i,j)[0]];
_I(i,j)[1] = table[_I(i,j)[1]];
_I(i,j)[2] = table[_I(i,j)[2]];
}
I = _I;
break;
}
}
return I;
}
该函数输入为数据类型及需求元素的坐标,返回的是一个对应的值-如果用 get 则是constant,如果是用 set 、则为non-constant. 处于程序安全,当且仅当在 debug 模式下 它会检查你的输入坐标是否有效或者超出范围. 如果坐标有误,则会输出一个标准的错误信息. 和高性能法(the efficient way)相比, 在 release模式下,它们之间的区别仅仅是On-the-fly方法对于图像矩阵的每个元素,都会获取一个新的行指针,通过该指针和[]操作来获取列元素.
当你对一张图片进行多次查询操作时,为避免反复输入数据类型和at带来的麻烦和浪费的时间,OpenCV 提供了:basicstructures:Mat_ <id3> data type. 它同样可以被用于获知矩阵的数据类型,你可以简单利用()操作返回值来快速获取查询结果. 值得注意的是你可以利用 at() 函数来用同样速度完成相同操作. 它仅仅是为了让懒惰的程序员少写点 >_< .
4. 核心函数LUT(The Core Function)¶
这是最被推荐的用于实现批量图像元素查找和更该操作图像方法。在图像处理中,对于一个给定的值,将其替换成其他的值是一个很常见的操作,OpenCV 提供里一个函数直接实现该操作,并不需要你自己扫描图像,就是:operationsOnArrays:LUT() <lut> ,一个包含于core module的函数. 首先我们建立一个mat型用于查表:
Mat lookUpTable(1, 256, CV_8U);
uchar* p = lookUpTable.data;
for( int i = 0; i < 256; ++i)
p[i] = table[i];
然后我们调用函数 (I 是输入 J 是输出):
LUT(I, lookUpTable, J);
性能表现¶
为了得到最优的结果,你最好自己编译并运行这些程序. 为了更好的表现性能差异,我用了一个相当大的图片(2560 X 1600). 性能测试这里用的是彩色图片,结果是数百次测试的平均值.
| Efficient Way | 79.4717 milliseconds |
| Iterator | 83.7201 milliseconds |
| On-The-Fly RA | 93.7878 milliseconds |
| LUT function | 32.5759 milliseconds |
我们得出一些结论: 尽量使用 OpenCV 内置函数. 调用LUT 函数可以获得最快的速度. 这是因为OpenCV库可以通过英特尔线程架构启用多线程. 当然,如果你喜欢使用指针的方法来扫描图像,迭代法是一个不错的选择,不过速度上较慢。在debug模式下使用on-the-fly方法扫描全图是一个最浪费资源的方法,在release模式下它的表现和迭代法相差无几,但是从安全性角度来考虑,迭代法是更佳的选择
最后,你可以在我们的YouTube频道上观看范例视频 <https://www.youtube.com/watch?v=fB3AN5fjgwc>.
翻译者¶
loveisp@ OpenCV中文网站
zhaowang@ OpenCV中文网站 <zhao.wang@student.xjtlu.edu.cn>
Help and Feedback
You did not find what you were looking for?- Ask a question in the user group/mailing list.
- If you think something is missing or wrong in the documentation, please file a bug report.